








Model pricing
Cursor plans include usage at the model API rates. For example, $20 of included usage on the Pro plan will be consumed based on your model selection and its price. Usage limits are shown in editor based on your current consumption. To view all model API prices, view the provider documentation:Auto
Enabling Auto allows Cursor to select the premium model best fit for the immediate task and with the highest reliability based on current demand. This feature can detect degraded output performance and automatically switch models to resolve it.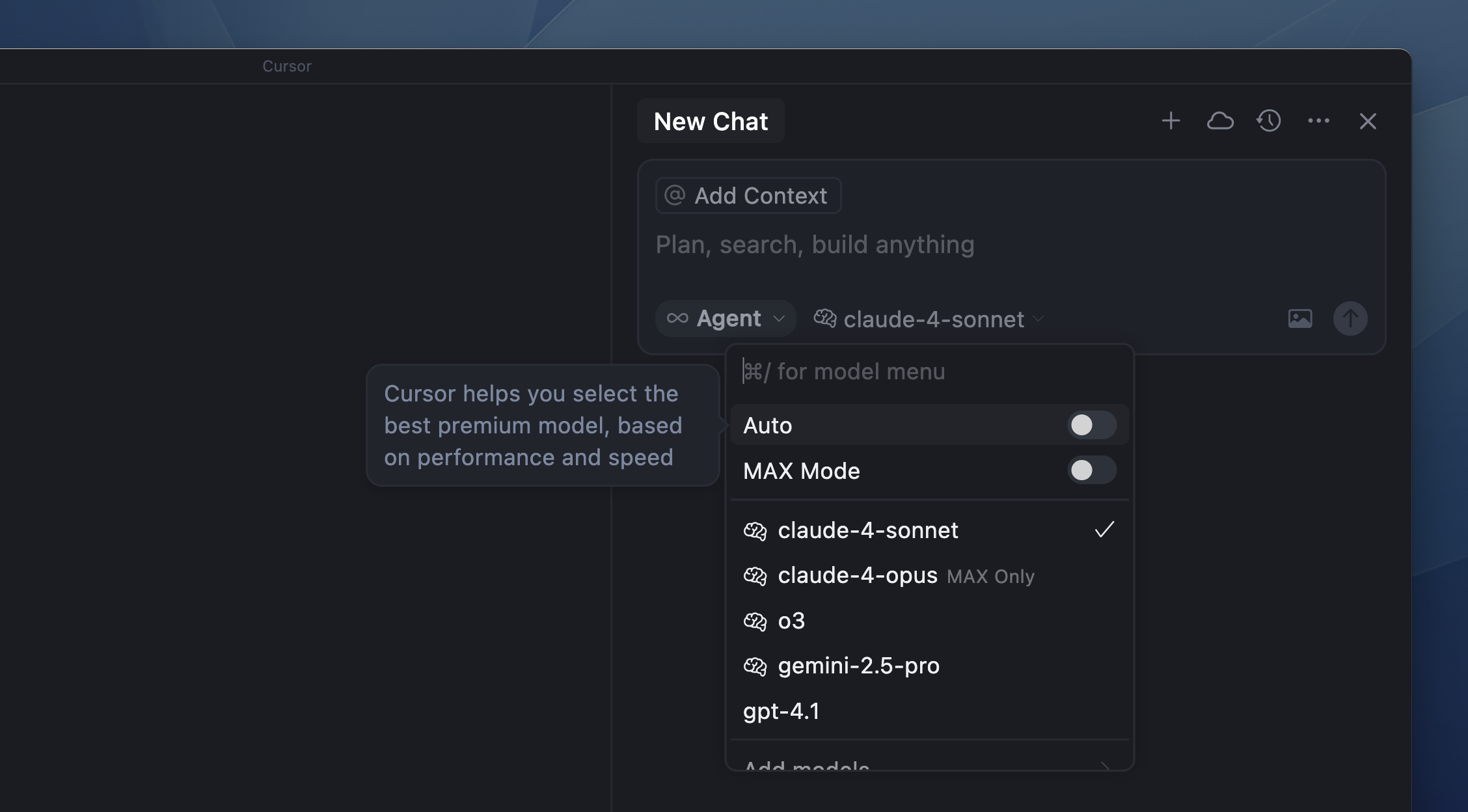
Context windows
A context window is the maximum span of tokens (text and code) an LLM can consider at once, including both the input prompt and output generated by the model. Each chat in Cursor maintains its own context window. The more prompts, attached files, and responses included in a session, the larger the context window grows. Learn more about working with context in Cursor.Max Mode
Normally, Cursor uses a context window of 200k tokens (~15,000 lines of code). Max Mode extends the context window to the maximum available for a handful of models. This will be a bit slower and more expensive. It is most relevant for Gemini 2.5 Flash, Gemini 2.5 Pro, GPT 4.1, and Grok 4, which have context windows larger than 200k.FAQ
Where are models hosted?
Where are models hosted?
Models are hosted on US-based infrastructure by the model’s provider, a trusted partner, or Cursor directly.When Privacy Mode is enabled, neither Cursor nor model providers store your data. All data is deleted after each request. For details see our Privacy, Privacy Policy, and Security pages.