Notebook development
For full notebook support, download the Jupyter (id: ms-toolsai.jupyter) extension, published by ms-toolsai.
.ipynb and .py files with integrated cell execution. Tab, Inline Edit, and Agents
work within notebooks, just as they do in other code files.
Key capabilities:
- Inline cell execution runs code directly within the editor interface
- Tab, Inline Edit, and Agent all understand data science libraries including pandas, NumPy, scikit-learn, and SQL magic commands
Database integration
Databases can be integrated with Cursor through two main mechanisms: MCP servers and Extensions.- MCP Servers let your Agents connect with your databases
- Extensions integrate your broader IDE with your databases
Via MCP
MCP servers allow your agent to make queries directly against your database. This allows your agent to choose to query your database, write the appropriate query, run the command and analyze outputs, all as part of an ongoing task. For example, you can connect a Postgres database to your Cursor instance by adding the following MCP config to Cursor:Via Extensions
Install database-specific extensions (PostgreSQL, BigQuery, SQLite, Snowflake) to execute queries directly from the editor. This eliminates context switching between tools and enables AI assistance for query optimization.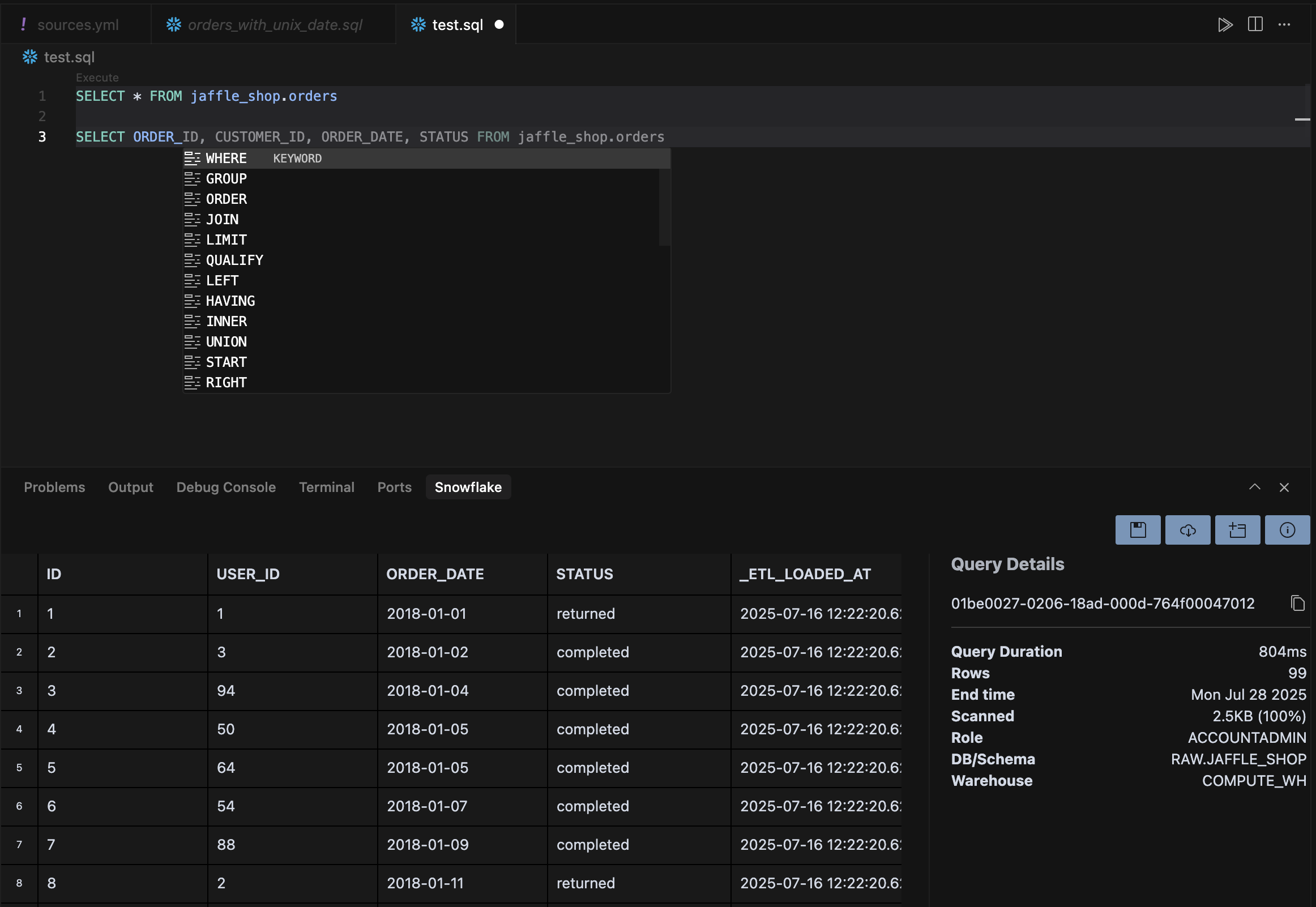
Data visualization
Cursor’s AI assistance extends to data visualization libraries including Matplotlib, Plotly, and Seaborn. The agent can generate code for data visualization, helping you quickly and easily explore data, while creating a replicable and shareable artifact.Frequently asked questions
Can I use existing Jupyter notebooks? Yes, Cursor opens.ipynb files with full cell execution and AI completion support.
How do I handle large datasets that don’t fit in memory?
Use distributed computing libraries like Dask or connect to Spark clusters through Remote-SSH connections to larger machines.
Does Cursor support R and SQL files?
Yes, Cursor provides AI assistance and syntax highlighting for R scripts (.R) and SQL files (.sql).
What’s the recommended way to share development environments?
Commit the .devcontainer folder to version control. Team members can rebuild the environment automatically when opening the project.
How do I debug data processing pipelines?
Use Cursor’s integrated debugger with breakpoints in Python scripts, or leverage Agent to analyze and explain complex data transformations step by step.
Environment reproducibility
Development containers
Development containers help you ensure consistent runtimes and dependencies across team members and deployment environments. They can eliminate environment-specific bugs and reduce onboarding time for new team members. To use a development container, start by creating a.devcontainer folder in your repository root. Next, create a devcontainer.json, Dockerfile, and requirements.txt file.
Reopen in Container.
Development containers provide several advantages:
- Dependency isolation prevents conflicts between projects
- Reproducible builds ensure consistent behavior across development and production environments
- Simplified onboarding allows new team members to start immediately without manual setup
Remote development with SSH
When your analysis requires additional compute resources, GPUs, or access to private datasets, connect to remote machines while maintaining your local development environment.- Provision a cloud instance or access an on-premises server with required resources
- Clone your repository to the remote machine, including the
.devcontainerconfiguration - Connect through Cursor: Ctrl+Shift+P → “Remote-SSH: Connect to Host”